机器学习的基础与应用
本文最后更新于 2024年7月12日 下午
概论
人工智能:以人类智能相似的方式做出反应的智能机器
机器学习:利用经验来改善机器自身的性能
人工智能 >> 机器学习 >> 深度学习
应用
计算机视觉领域的主要应用
- 图像分类:根据图像的语义信息对不同类别图像进行区分。
- 目标检测:在图像找出其中所有目标的位置,并给出每个目标的具体类别。
- 语义分割:对图像中的每个像素打上类别标签进行分类。
- 实例分割:不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例。
自然语言处理领域的主要应用
- 情感分析:分析文本体现的情感。
- 机器翻译:基于统计语言模型的多语种互译。
- 自动摘要:根据文本自动生成摘要。
- 阅读理解:通过阅读文本回答问题、完成选择题或完型填空。
- 自然语言推理:根据一句话(前提)推理出另一句话(结论)。
- 聊天机器人:是经由对话或文字与人进行交谈。
语音识别领域的主要应用
- 语音识别:将语音识别为文字。
- 声纹识别:识别是哪个人的声音。
- 语音合成:根据文字合成特定人的语音。
什么是机器学习?

机器学习的基础概念
| 术语 terms | 房价预测案例 |
|---|---|
| 数据(raw data) | 房子1,房子2,房子3,房子4 |
| 特征 | 卧室个数,地理位置,朝向,… /不具有可解释性 |
| 模型 | 支持向量机,神经网络,… |
| 参数 | 可学习的,根据目标函数进行优化的 |
| 模型输出 | 预测的房价 |
| 目标 | 真实的房价 |
| 目标函数(损失函数) | |
| 训练集 | 用于训练模型的数据集 |
| 测试集 | 用于评估已训练模型的数据集 |
| 泛化 | 衡量模型对未见过数据样本的分类能力 |
| 术语 terms | 案例 |
|---|---|
| 超参数 | 模型外部的变量 |
| 误差 | 模型输出与目标的差值 |
| 欠拟合 | 在训练集、测试集上均表现不佳 |
| 过拟合 | 在训练集上表现很好,在测试集上表现不佳 |
| 验证集 | 用于模型自身性能评估及超参数调整 |
| 性能度量 | 准确率,错误率,查全率,查准率 |
| 偏差 | 模型在样本上的输出与真实值之间的误差,衡量模型拟合训练数据的能力 |
| 方差 | 模型每一次输出结果与模型输出期望之间的误差,衡量模型的稳定性 |
| 噪声 | 描述了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度 |
机器学习的主要分类
监督学习(Supervised learning)
训练数据有目标向量(标签)—— 分类、回归
非监督学习(Unsupervised learning)
训练数据没有目标向量(标签)—— 聚类、密度估计、可视化…
半监督学习(Semi-supervised learning)
有标签数据 + 无数据标签 —— 伪标签
强化学习(Reinforcement learning)
和环境存在交互 —— situation, action, reward
监督学习
regression 回归
给定数据集
$$
D = {(\vec{x_1},y_1),(\vec{x_2},y_2),……,(\vec{x_m},y_m)}
$$
其中,$\vec{x_i} = (x_{i1};x_{i2};……;x_{id})$, $y_i \in R$
$\vec{x}$ :输入变量/“特征” $y$ :输出变量/目标变量
线性回归(linear regression):学得一个线性模型以尽可能准确地预测实值输出标记
$$
f(\vec{x}) = \omega_1x_1 + \omega_2x_2 + …… +\omega_dx_d + b
$$
$\vec{x} = (x_1;x_2;……;x_d)$ 是描述特征,其中 $x_i$ 是 $\vec{x}$ 的第 $i$ 类特征取值
向量形式
$$
f(\vec{x}) = \vec{\omega}^{\mathrm{T}} \vec{x} + b
$$
其中,$\vec{\omega} = (\omega_1;\omega_2;……;\omega_d)$
线性回归(linear regression)的目的:$f(\vec{x_i})\approx y_i$
其中的重点在于确定 $\vec{\omega}$ 和 $b$ 的值
最小化均方误差:$(\omega,b) = \text{argmin}\sum_{i= 1}^{m} {(f(x_i)-y_i)^{2}} = \text{argmin}\sum_{i= 1}^{m} {(y_i - \omega x_i - b)^{2}}$
梯度下降算法*
$$
\omega_j^t = \omega_j^{t - 1} - \alpha \frac{\partial}{\partial \omega_j}J(W)
$$
二分法
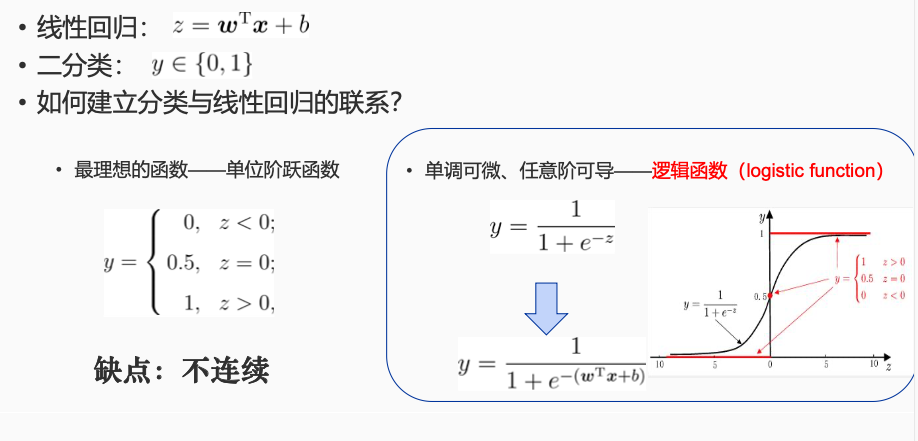
线性回归:$z = \vec{\omega}^{\mathrm{T}} \vec{x} + b$
二分类:$y \in {0,1}$
用单调可微、任意阶可导的逻辑函数(logistic function)去逼近单位阶跃函数(缺点:不连续)
应用实例
疼痛风险评估
背景:慢性疼痛是一种复杂的疾病,受生物、心理和社会因素的综合影响。临床上慢性疼痛的原因及其预后通常是未知的,因为难以根据组织损伤准确预测临床结果。目前缺少一个具有临床效用的数据驱动框架来预测疼痛状况。
使用非线性迭代偏最小二乘(NIPALS)回归算法可以实现对疼痛风险的评估。
输入:包含以下三大类别的99维特征。
- 身体健康:物质使用、睡眠、体育活动、人体测量
- 心理健康:情绪、神经质、生活的压力
- 社会人口:社会经济、职业、人口
输出:将疼痛部位数量看作风险得分进行预测。
结果:基于疼痛风险,实现 不同部位疼痛预测精度达70%-88%
fMRI 分类
定义:功能性磁共振成像(fMRI,functional Magnetic Resonance Imaging)是一种非侵入性的脑成像技术,通过测量大脑不同区域的血氧水平依赖(BOLD)信号,能够检测大脑在进行特定任务时的活动变化。
应用:fMRI数据通过揭示大脑在不同心理或认知状态下的活动模式,可以帮助医生和研究人员诊断疾病、理解心理状态、评估神经疾病的影响。
研究目的:为了分析睡眠时的大脑状态,挖掘不同状态类型的脑区激活情况,揭示清醒与睡眠状态之间大脑功能的连续性和转换机制。
研究内容:扫描清醒状态下受到中性/负性视觉刺激的fMRI数据,根据清醒fMRI数据构建分类模型,学习大脑如何在不同情绪和认知状态下处理信息,随后预测睡眠fMRI数据对应的大脑状态。
非监督学习
给定数据集无标签信息
没有监督信息的情况下,依赖数据本身找到内在的聚集关系
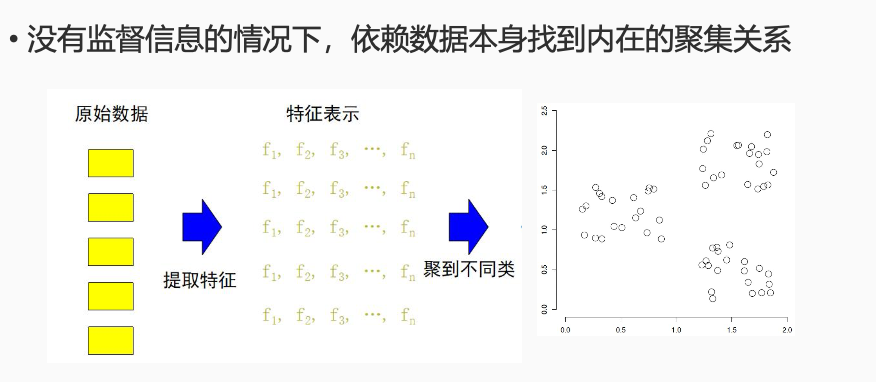
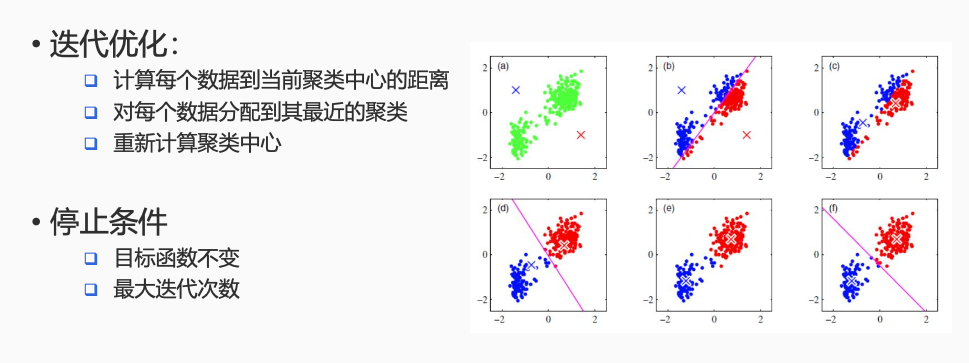
K-means聚类
牧师-村民模型
- 有4个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课。
- 听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。
- 牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个村民又去了离自己最近的布道点……
- 就这样,牧师每个礼拜更新自己的位置,村民根据自己的情况选择布道点,最终稳定了下来。
数学实现
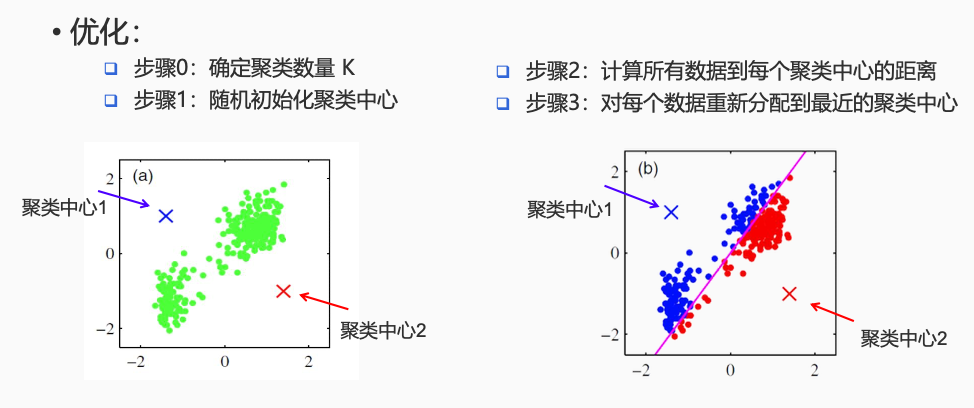
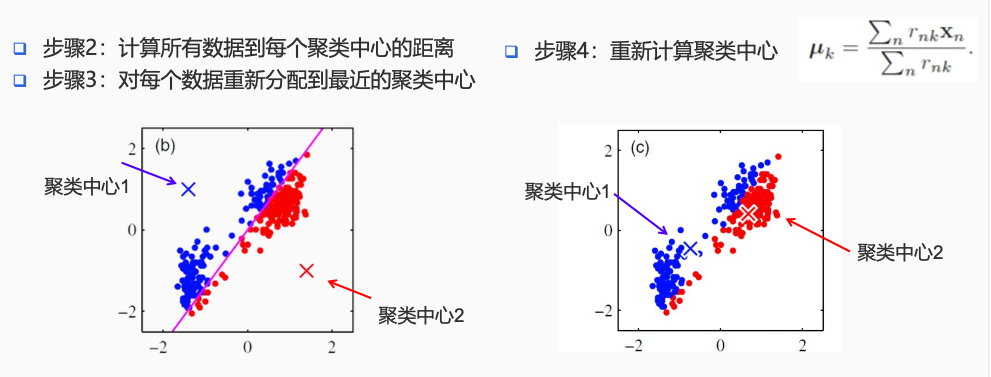
问题:给定数据集 ${x_1,……,x_N}$,发现 $K$ 个聚类
模型:每个数据分配给距离最近的类 $k = \text{argmin}_j ||x_n - \mu_j||^2$
优化目标:寻找聚类(中心 $\mu_k$ )使得所有数据到其聚类中心距离和最小 $J = \sum_{n = 1}^K \sum_{k = 1}^K{r_{nk}||x_n - \mu_||^2}$
$r_{nk} = \begin{cases}
1, & \text{if }k = \text{argmin}_j ||x_n - \mu_j||^2 ;
0, & \text{otherwise}
\end{cases}$
聚类
应用事例:脑电波微状态分析
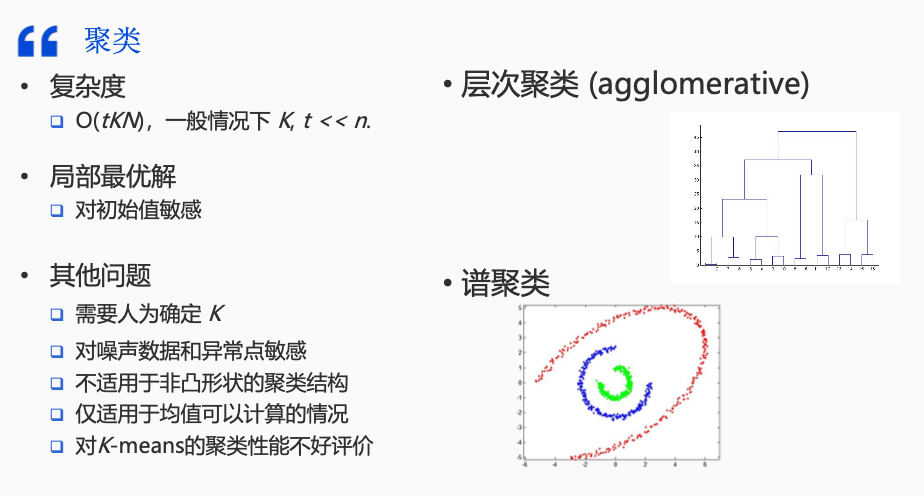
降维
问题:当数据维度增长,分类空间爆炸增长
降维:即通过某种数学变换,将原始高维属性空间转变为一个低维“子空间“,在这个子空间中样本密度大幅度提高,距离计算也变得更为容易
降维-PCA算法
降维-SVD算法
一般用于推荐系统
前沿挑战
泛化性问题
安全性问题
案例-智能 X 光违禁品检测
背景:由于安检X光成像识别过程复杂,专业安检人员往往需要频繁换岗来应对日益增长的公共交通系统压力,导致人力资源消耗巨大,并且存在漏检、误检的情况,危害社会安全。利用卷积神经网络等深度学习技术可实现X光图像中违禁品的自动化精准检测,保护国家与社会公共安全。

案例-Deep Fake
对抗危机
全新类型的攻击:对抗样本、噪音污染、数据投毒、数据伪造
对抗样本是一类被恶意设计来攻击机器学习模型的样本。
与真实样本的差异不易感知;可以导致模型进行错误的判断
讲课教师
BUAA-马宇晴