卷积入门——图像模糊
本文最后更新于 2024年7月18日 凌晨
卷积的定义
一维卷积的定义
$$
c_k=\sum_{i+j=k+1}a_ib_j,\quad k=1,\ldots,n+m-1,
$$
我们一般将这样的卷积操作记作 $c = a *b$
举一个例子,假如 a 是一个四维向量,而 b 是一个三维向量,那么他们的卷积操作就是以下形式
$$
\begin{aligned}&c_{1}=\quad a_{1}b_{1}\& c_{2}=\quad a_{1}b_{2}+a_{2}b_{1}\& c_{3}=\quad a_{1}b_{3}+a_{2}b_{2}+a_{3}b_{1}\& c_{4}=\quad a_{2}b_{3}+a_{3}b_{2}+a_{4}b_{1}\& c_{5}=\quad a_{3}b_{3}+a_{4}b_{2}\& c_{6}=\quad a_{4}b_{3}.\end{aligned}
$$
对于连续的函数,卷积的公式为
$$
(f*g)(n)=\int_{-\infty}^\infty f(x)g(n-x)dx
$$
那么,问题是,这样卷积的意义是什么呢?
其实,仔细观察你可以发现卷积的操作不过是用一个函数的翻转去乘以另一个函数,再逐个相加得到一个值。注意:得到的是一个数值,不是向量或者函数。
一般来说,数学上卷积的意义为:两个函数通过翻转和平移后,在其重叠部分进行积分的一种数学运算。它本质上是一种特殊的积分变换,用于描述一个函数如何影响另一个函数。
对于这样抽象的定义,我们肯定是不能很好地理解的,所以不妨来看一下它的相关运用
多项式相乘
如果上诉的 a 和 b 代表两个多项式:
$$
p(x)=a_1+a_2x+\cdots+a_nx^{n-1},\quad q(x)=b_1+b_2x+\cdots+b_mx^{m-1},
$$
那么这两个多项式的相乘就为:
$$
p(x)q(x)=c_1+c_2x+\cdots+c_{n+m-1}x^{n+m-2}
$$
其中,你可以发现每一个 c 正好是对应的卷积的值遵循这个公式 $c_{k} = \sum_{i+j=k+1}a_{i}b_{j}$
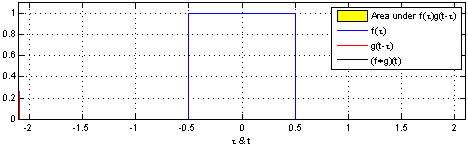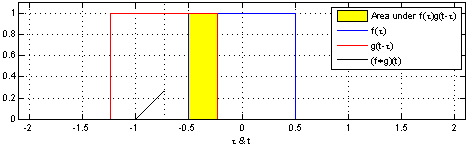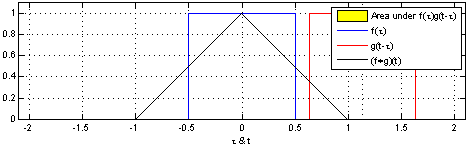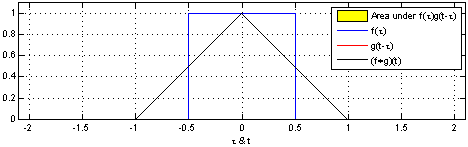
时间序列平滑
以下图片展示了一个很形象的例子
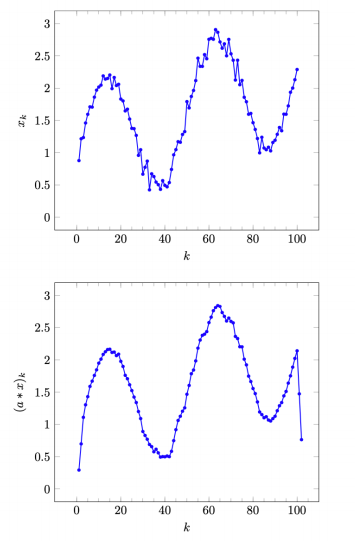
直观上来看,第一幅的点是的连续性很差,他们肯多都是跳跃性的,相反第二副图通过 a = (1/3, 1/3, 1/3) 的卷积后,相当于对每个点和它周围的两个点取平均,使得最后的图像趋于平滑
示例
图像模糊
与上一个例子相似,你应该也可以猜出来为什么卷积可以运用到图像模糊上去。对于一张图片,如果每个像素点的 RGB 进行卷积操作,就会让这个点的 RGB 和周围点的 RGB 值趋于平滑的变化,从而可以达到图像模糊的效果,下面我会深入探讨图像模糊的卷积操作
二维卷积的定义
对于二维卷积,和一维卷积的定义有类似的地方,假设 A 是一个 m * n 的矩阵,而 B 是一个 p * q 的矩阵,那么他们卷积完的矩阵就为
$$
C_{rs}=\sum_{i+k=r+1, j+l=s+1}A_{ij}B_{kl},\quad r=1,\ldots,m+p-1,\quad s=1,\ldots,n+q-1,
$$
需要注意的是:当超过矩阵的边界进行卷积处理时,我们假设边界外的值都为 0
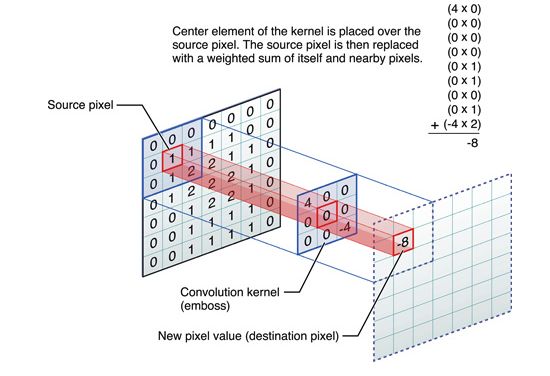

二维卷积的最常见运用场景便是针对于图像的卷积操作
简单的图像卷积例子
考虑一张黑白图片,它可以用 8 * 9 维矩阵 X 表示
$$
\left.X=\left[\begin{array}{ccccccccc}1&1&1&1&1&1&1&1&1 \ 1&1&1&1&1&1&1&1&1\ 1&1&0&0&0&0&0&1&1\ 1&1&1&0&1&1&0&1&1\ 1&1&1&0&1&1&0&1&1\ 1&1&1&0&1&1&0&1&1\ 1&1&1&1&1&1&1&1&1\ 1&1&1&1&1&1&1&1&1\end{array}\right.\right]
$$
然后再引入另一个矩阵 B
$$
B=\left[\begin{array}{cc}1/4&1/4\ 1/4&1/4\end{array}\right]
$$
接着对这两个矩阵进行卷积操作就可以得到一个新的 9 * 10 维矩阵
$$
X\star B=\left[\begin{array}{cccccccccc}1/4&1/2&1/2&1/2&1/2&1/2&1/2&1/2&1/2&1/4\ 1/2&1&1&1&1&1&1&1&1&1/2\ 1/2&1&3/4&1/2&1/2&1/2&1/2&3/4&1&1/2\ 1/2&1&3/4&1/4&1/4&1/2&1/4&1/2&1&1/2\ 1/2&1&1&1/2&1/2&1&1/2&1/2&1&1/2\ 1/2&1&1&1/2&1/2&1&1/2&1/2&1&1/2\ 1/2&1&1&3/4&3/4&1&3/4&3/4&1&1/2\ 1/2&1&1&1&1&1&1&1&1&1/2\ 1/4&1/2&1/2&1/2&1/2&1/2&1/2&1/2&1/2&1/4\end{array}\right].
$$
最后原图像和卷积后的图像的对比如下图所示,非常有意思是不是,实现了一种平滑模糊的效果

图像的相关知识
在我们实现图像模糊之前我们先要学习一下关于图像的相关知识
Mode 色彩模式
首先我们要介绍的是图像的色彩模式,它决定了图像当中色彩的表现方式,常见的图像 mode 包括 RGB 和 L,这些 mode 影响了图像处理和显示的方式
L 模式(Luminance)
这通常也被称作为单通道模式或者灰度模式,这其中每个像素仅由一个通道表示,值的大小范围是 0~255。(8 比特)
0 表示纯黑色,255 表示纯白色
值越大画面越白
这也可以称作 8 位色深图像,总共可以表示 $2^{8}=256$ 种颜色
RGB 模式(Red,Blue,Green)
这种模式也被称作真色彩模式,每个像素由红、蓝、绿三个通道组成,每个通道的值的大小范围也是 0~255。(24 比特)
其中值的大小和 L 模式一样,表示亮度/强度
这也可以称作 24 位色深图像,总共可以表示 $2^{24}=16,777,216$ 种颜色,因为能表示的颜色数量接近人眼能辨别的色彩范围,就叫做真彩色模式。
RGBA 模式(Red,Blue,Green,Alpha)
相比于 RGB 模式,这种模式新增了一个 Alpha 通道表示透明度,它的值的大小也是 0~255。(32 比特)
值越大,透明度越高
这在需要处理透明效果或图像叠加的应用中非常有用,例如图像编辑、视频特效和游戏开发中。
这也可以称作 32 位色深图像
图像的格式
常见的图像格式有以下几种:
JPEG(Joint Photographic Experts Group)
PNG(Portable Network Graphics)
GIF(Graphics Interchange Format)
BMP(Bitmap)
TIFF(Tagged Image File Format)
WebP
其中最重要的是 BMP 格式,它表示的是原始的图像格式,没有进行任何的压缩处理,通俗的来说,它使用的就是原始的矩阵表示图像,使得它能够精确地表示每个像素的颜色信息。
图像的矩阵表示
为了能够进行我们上诉的二维卷积运算,我们首先要做的操作是将图像转化为矩阵形式表示。但由于图像格式的多样性,对于特定格式的图像,我们需要单独处理它的二进制信息,这是一项复杂的操作。
以下是一个图像的像素分布

所以为了简便,我们将直接调用 Python 中的 Pillow 标准库来提取任何格式图像的矩阵信息
1 | |
此时我们打印出结果(注意 jpg 格式的图片是三通道类型)
1 | |
1 | |
可以看到这张图片的大小是 150*150,然后我们打印出了矩阵第一行的数值,包含 150 个三通道数值。由于是黑白照片,可以看到每个数值的每个通道的值都是相等的
如果我们打印的是彩色的照片,那么结果将是这样
1 | |
可以看到彩色照片的话三通道的值是各不相同的。
均值模糊
首先我们来尝试一种最简单的卷积计算——均值卷积,顾名思义就是用一个均值的矩阵与原图像进行卷积,常用的均值卷积是如下形式
$$
\begin{bmatrix}\frac{1}{9}&\frac{1}{9}&\frac{1}{9}\\frac{1}{9}&\frac{1}{9}&\frac{1}{9}\\frac{1}{9}&\frac{1}{9}&\frac{1}{9}\end{bmatrix}
$$
这样用于卷积运算的矩阵通常称作卷积核。不难发现,当我们用这样的卷积核进行运算的时候,可以让中心像素点和周围八个像素点达到平均取值的效果,从而实现平滑过渡的模糊效果。下面我将讲解我的 Python 代码实现均值卷积操作
Python 代码实现
为了更好的理解卷积的原理,我这里并没有调用 openCV 的函数库,而是自己实现的卷积操作,同样我也没有使用 numpy 库来简化矩阵运算的一些操作。
前期准备,首先要保证能像我上诉所讲的 pillow 库中一样对图像进行矩阵化处理,接下来我们定义一个函数
1 | |
最后我们再调用这个函数可得
1 | |
结果展示
示例 1
原图

卷积核大小为 3

卷积核大小为 5

卷积核大小为 7

卷积核大小为 9

卷积核大小为 11

卷积核大小为 13

示例 2
原图

卷积核大小为 3

卷积核大小为 7

卷积核大小为 11

卷积核大小为 15

卷积核大小为 31

可以从事例中看出
当卷积核的大小逐渐增加时,图片的模糊效果会增加,程序运行时长也会增加。
并且对于尺寸越小的图片,模糊的效果越明显,程序运行时间也会变多。
问题:黑边的出现
仔细观察图像可以发现当卷积核大小逐渐增加时,右边和下边会出现黑边,出现这种现象的原因是没有处理边界情况。下面我们来进行详细的说明。
padding:填补
在卷积操作中,边界像素的邻域像素比中心像素少。没有 padding 时,边界像素参与卷积的次数更少,导致边界信息在卷积过程中逐渐丢失。通过 padding,可以确保所有像素都有足够的邻域信息参与卷积操作,保留边界特征。
在没有 padding 的情况下,卷积操作会导致输出图像的尺寸变小。对于一个 𝑁×𝑁 的图像,使用 𝐾×𝐾 的卷积核,输出图像的尺寸会变为 (𝑁−𝐾+1)×(𝑁−𝐾+1)。这在多层卷积中会导致尺寸快速减小。通过添加 padding,可以保持输入和输出图像的尺寸一致。例如,使用适当的 padding 后,输出图像的尺寸可以保持为 𝑁×𝑁。
一般来说,有几种 padding 方式:
Zero padding
Reflect padding
Replicate padding……
对于 Python 中实现 padding,为了方便,我将用 numpy 库进行演示
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
最后我们选择了零填充优化改进了我们卷积的代码
1 | |
1 | |
然后我们运用了十次均值卷积操作,可以看见黑边已经消失了

问题:卷积核大小为什么为奇数
- 对称处理输入数据: 对称的卷积核能够均匀地处理输入数据,从而避免引入方向性偏差。例如,使用 3 x 3 的卷积核处理图像时,中心像素周围的每个像素都被均匀地考虑到了。
- 对齐卷积操作: 中心位置使得卷积操作在应用时能够以中心为参考点,从而确保卷积核对称地应用于输入图像的各个像素。
- 输出与输入对齐: 奇数大小的卷积核使得输入图像的每个像素都能够被卷积核的中心对齐,从而使输出特征图的像素与输入图像的像素位置对应关系更明确。例如,3 x 3 卷积核在应用于输入图像的边界像素时,能够保证输出图像的中心位置与输入图像的中心位置对齐。
- 填充(padding)操作的对称性: 在使用填充操作时,奇数大小的卷积核能够使填充更均匀。
openCV
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,广泛应用于实时图像处理和计算机视觉任务中。
OpenCV提供了丰富的图像处理和计算机视觉算法,包括图像转换、滤波、特征检测、对象识别、摄像机标定、运动跟踪等。它支持多种编程语言,包括C++、Python、Java和MATLAB等,使得开发者可以根据自己的偏好和项目需求选择合适的编程语言。
关键:由于 openCV 的绝大部分库是由 C 和 C++ 语言编写,并且OpenCV利用了许多高性能计算库,如BLAS(Basic Linear Algebra Subprograms)和LAPACK(Linear Algebra PACKage)进行矩阵运算,加速线性代数计算。
我们利用了自己写的函数与 openCV 提供的均值模糊函数进行了对比,在结果上并无差异,但是在速度上却相差许多。
我们主要是用 11 * 11 的均值模糊矩阵循环模糊了 10 次,我们自己编写的函数大概需要 10 秒以上才可以得出结果,但是调用 openCV 的库却可以做到瞬间生成图片。
1 | |
以下是一组对比的事例
原图

自己的函数实现——Zero padding

自己的函数实现——Replicate padding

openCV 库实现

高斯模糊
高斯模糊(Gaussian Blur)是一种常用的图像处理技术,用于减少图像中噪声和细节,平滑图像以改善后续处理步骤的效果。它是基于统计学中的高斯分布(正态分布)来计算每个像素周围区域的加权平均值,从而实现模糊效果。
一维的正态分布函数为
$$
f(x)=\frac1{\sqrt{2\pi}\mathrm{~}\sigma}\mathrm{exp}\left[-\frac{(x-\mu)^2}{2\sigma^2}\right]
$$
对于我们要处理的 2 维图像,需要二维的正态分布
$$
f(x,y)=\frac1{2\pi\sigma_x\sigma_y}\exp\left(-\frac12\left(\frac{(x-\mu_x)^2}{\sigma_x^2}+\frac{(y-\mu_y)^2}{\sigma_y^2}\right)\right)
$$
一般来说高斯模糊的卷积核有以下几种
3 * 3
$$
\frac{1}{16}\begin{bmatrix}1&2&1\ 2&4&2\ 1&2&1\end{bmatrix}
$$
5 * 5
$$
\frac{1}{273}\begin{bmatrix}1&4&7&4&1\ 4&16&26&16&4\ 7&26&41&26&7\ 4&16&26&16&4\ 1&4&7&4&1\end{bmatrix}
$$
7 * 7
$$
\frac{1}{1003}\begin{bmatrix}0&0&1&2&1&0&0\ 0&3&13&22&13&3&0\ 1&13&59&97&59&13&1\ 2&22&97&159&97&22&2\ 1&13&59&97&59&13&1\ 0&3&13&22&13&3&0\ 0&0&1&2&1&0&0\end{bmatrix}
$$
我们选取的是 7 * 7 的高斯卷积核进行试验,首先在 python 中定义这样的卷积核
1 | |
再用 7 * 7 的均值卷积核进行对比
1 | |
原图

结果输出为
均值模糊

高斯模糊

运用openCV 的库的图像对比为
均值模糊

高斯模糊

其实,仔细观察会发现:
由于高斯模糊的正太分布,导致中心元素的权值会高于周围元素的权值,并不像均值模糊那样的平均化,所以说,即使模糊了也不会像均值模糊那样模糊掉物体的轮廓。相反,高斯模糊更接近与人眼的近视模糊效果,保留了物体的轮廓特征平提高了图像的整体质量。
这样的模糊效果在后续的特征提取、边缘检测等算法中很有用。
与 PS 的联系
如果你使用过关于 ps 的一系列软件的话,你会发现这些软件基本上都有一项功能——高斯模糊
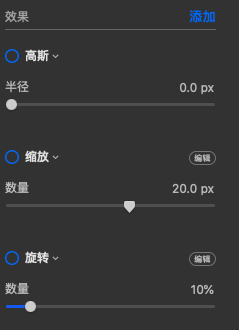
以图像处理软件 Pixelmator Pro 为例,在效果功能中,有一个选项就是“高斯效果”,其原理就是高斯模糊,当我们把半径调大时,高斯模糊的效果就会越明显,就相当于更多次的高斯卷积或者使用了更大高斯卷积核。
这一张图是我使用软件得到的高斯半径为 3px 的图像,与我们上述处理的效果近似

这一张则是我使用软件得到的高斯半径为 30px 的图像

所以,图像卷积得到的图像模糊效果是在工业界有实际运用场景的。