本文最后更新于 2024年7月18日 凌晨
Xpath 数据提取 Xpath 语法 在浏览器的任意界面,按下 F12 打开开发者工具后,查看 Elements 属性,再按下 Ctrl + f 开启搜索模式,便可以输入 Xpath 语法进行搜索查找。
Xpath 简介
开源的 Xpath 表达式编辑工具:XMLQuire(XML 格式文件可用)—— 类似于 HTML 文件格式
Chrome 插件 XPath Helper
选取节点 Xpath 使用路径表达式来选取 XML 文档中的节点或者节点集,这些路径表达式和我们在常规电脑文件系统中看到的表达式非常相似
表达式
描述
nodename
选取此节点的所有子节点
/
从根节点选取(取子节点)
//
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)
.
选取当前节点
..
选取当前节点的父节点
@
选取属性
示例
路径表达式
描述
div
选取 div 元素的所有子节点
/div
选取根元素 div 。假设路径起始于正斜杠 / ,则此路径始终代表到某元素的绝对路径
div/a
选取属于 div 的子元素的所有 a 元素
//div
选取所有 div 子元素
div//p
选取属于 div 元素的后代的所有 p 元素,而不管它们位于 div 之下的什么位置
//@lang
选取名为 lang 的所有属性
谓语(条件过滤) 谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中
路径表达式
描述
/ul/li[1]
选取属于 ul 子元素的第一个 li 元素
/ul/li[last()]
选取属于 ul 子元素的最后一个 li 元素
/ul/li[last()-1]
选取属于 ul 子元素的倒数第二个 li 元素
/ul/li[position()<3]
选取最前面两个属于 ul 元素的子元素的 li 元素
//div[@attr]
选取所有拥有名为 attr 的属性的 div 元素
//div[@attr=’leng’]
选取所有 div 元素,且这些元素拥有值为 leng 的 attr 属性
选取未知节点
通配符
描述
*
匹配任何元素节点
@*
匹配任何属性节点
示例
路径表达式
描述
/div/*
选取 div 元素的所有子元素
//*
选取文档中的所有元素
html/node()/a/@*
选择 html 下面任意节点下面的 a 节点的所有属性
//div[@*]
选取所有带有属性的 div 元素
模糊匹配 1 2 3 [contains(@属性,值) ]# 选取属性为attr,并且值为100的所有元素
获取数据 获取文本数据 选中节点后要获取节点中的文本内容,使用text()方法
获取属性值 Python 中的Xpath 首先要知道的是 Xpath 处理的是 XML 格式的文档,所以在 Python 中我们需要一个专门用来解析 XML 文档的库——lxml
在命令行窗口中运行这段命令便可以安装成功
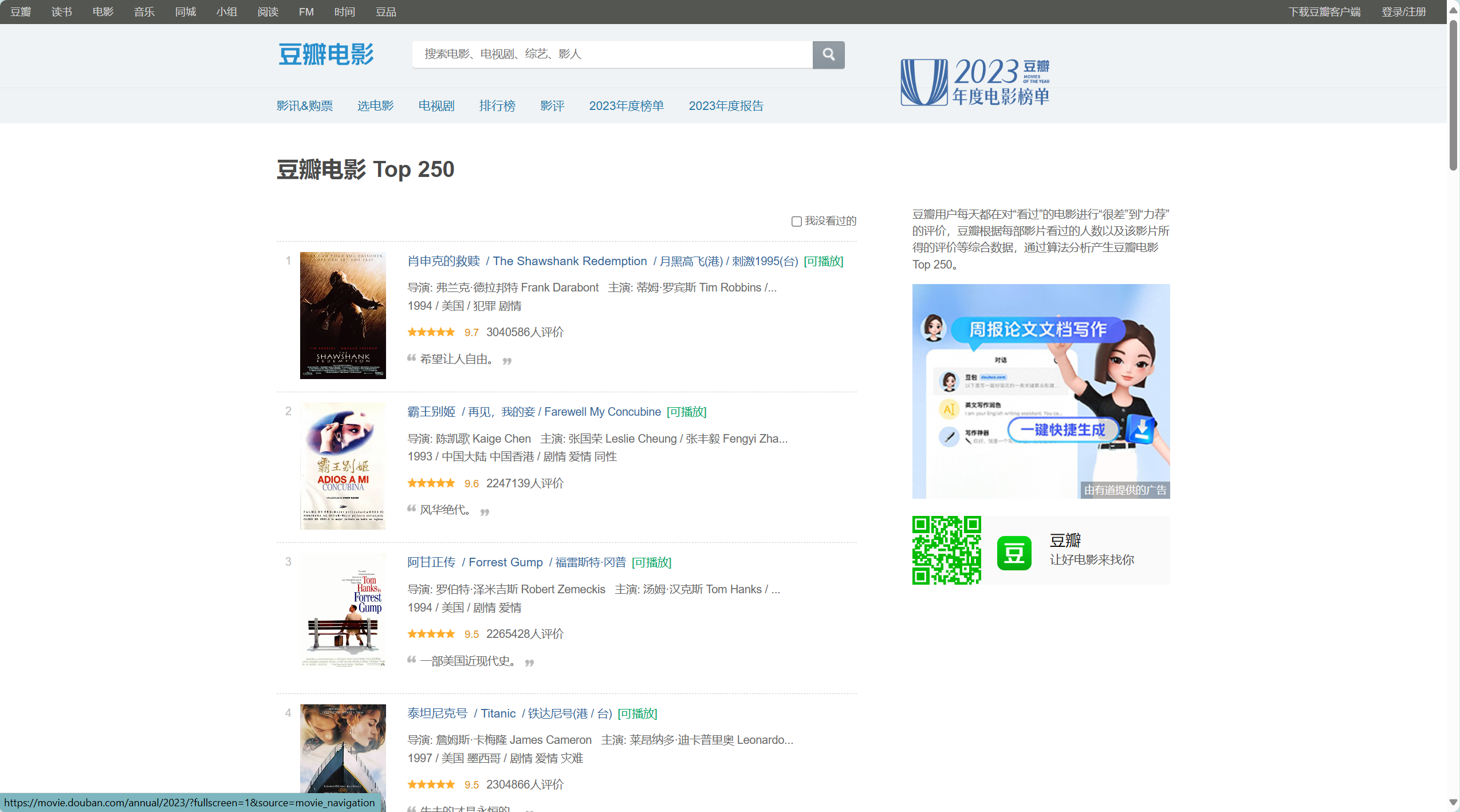
豆瓣 TOP 250
下面我们来看一个简单的例子,爬取豆瓣 TOP250 第一页的所有电影名,我先把代码给出,大家可以细细观察一下如何使用 Python 中的 Xpath
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from lxml import etreeimport requests"https://movie.douban.com/top250" "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36 Edg/89.0.774.77" ,if response.status_code == 200 :"utf-8" )"//*[@class='title'][1]/text()" )print (titles)else :print ("请求失败" )
得到的结果为
1 ['肖申克的救赎 ', '霸王别姬 ', '阿甘正传 ', '泰坦尼克号 ', '千与千寻 ', '这个杀手不太冷 ', '美丽人生 ', '星际穿越 ', '盗梦空间 ', '楚门的世界 ', '辛德勒的名单 ', '忠犬八公的故事 ', '海上钢琴师 ', '三傻大闹宝莱坞 ', '放牛班的春天 ', '机器人总动员 ', '疯狂动物城 ', '无间道 ', '控方证人 ', '大话西游之大圣娶亲 ', '熔炉 ', '教父 ', '触不可及 ', '当幸福来敲门 ', '寻梦环游记 ']
可以看到一共有 25 部电影,正好相符于网页的内容
接着,我们再来尝试一下获取每部电影的评分,需要修改代码为
1 2 3 4 5 titles = html.xpath("//*[@class='title'][1]/text()" )"//*[@class='rating_num'][1]/text()" )for i in range (25 ):print ("电影:" , titles[i], "评分:" , scores[i])
得到的结果为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 电影: 肖申克的救赎 评分: 9.7
除了这种方式实现一对一的对应以外,我们还可以通过获取父节点的方式来实现
1 2 3 4 5 6 7 8 9 10 11 12 13 if response.status_code == 200 :"utf-8" )"//ol/li" )for li in data_list:".//span[@class='title'][1]/text()" )".//span[@class='rating_num'][1]/text()" )print ("电影:" , title, "评分:" , score)
注意找到父节点之后再找子节点时,需要加上一个 . 表示从当前节点开始向下查找。
运行得到的结果为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 电影: ['肖申克的救赎' ] 评分: ['9.7' ] ['霸王别姬' ] 评分: ['9.6' ] ['阿甘正传' ] 评分: ['9.5' ] ['泰坦尼克号' ] 评分: ['9.5' ] ['千与千寻' ] 评分: ['9.4' ] ['这个杀手不太冷' ] 评分: ['9.4' ] ['美丽人生' ] 评分: ['9.5' ] ['星际穿越' ] 评分: ['9.4' ] ['盗梦空间' ] 评分: ['9.4' ] ['楚门的世界' ] 评分: ['9.4' ] ['辛德勒的名单' ] 评分: ['9.5' ] ['忠犬八公的故事' ] 评分: ['9.4' ] ['海上钢琴师' ] 评分: ['9.3' ] ['三傻大闹宝莱坞' ] 评分: ['9.2' ] ['放牛班的春天' ] 评分: ['9.3' ] ['机器人总动员' ] 评分: ['9.3' ] ['疯狂动物城' ] 评分: ['9.2' ] ['无间道' ] 评分: ['9.3' ] ['控方证人' ] 评分: ['9.6' ] ['大话西游之大圣娶亲' ] 评分: ['9.2' ] ['熔炉' ] 评分: ['9.4' ] ['教父' ] 评分: ['9.3' ] ['触不可及' ] 评分: ['9.3' ] ['当幸福来敲门' ] 评分: ['9.2' ] ['寻梦环游记' ] 评分: ['9.1' ] ['当幸福来敲门' ] 评分: ['9.2' ] ['当幸福来敲门' ] 评分: ['9.2' ] ['当幸福来敲门' ] 评分: ['9.2' ] ['当幸福来敲门' ] 评分: ['9.2' ] ['当幸福来敲门' ] 评分: ['9.2' ] ['寻梦环游记' ] 评分: ['9.1' ]
然后可以对代码进行稍加改进
1 print ("电影:" , title[0 ], "评分:" , score[0 ])
得到的结果便和前面是一样的了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 电影: 肖申克的救赎 评分: 9.7
举一反三,你还可以提取其他属性的内容——导演、演员……
分页抓取数据 观察豆瓣 TOP250 的网址可以发现
第 1~25 在网址豆瓣电影 Top 250 (douban.com)
第 26~50 在网址豆瓣电影 Top 250 (douban.com)
第 51~75 在网址豆瓣电影 Top 250 (douban.com)
第 76~100 在网址豆瓣电影 Top 250 (douban.com)
所以我们便可以改进 Python 代码实现自动化分页爬取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from lxml import etreeimport requestsclass DouBan :"https://movie.douban.com/top250?start={}&filter=" def __init__ (self ):self .url_list = []for i in range (10 ):self .base_url.format (i * 25 )self .url_list.append(url)def get_page_data (self, url ):"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36 Edg/89.0.774.77" ,if response.status_code == 200 :"utf-8" )"//ol/li" )for li in data_list:".//span[@class='title'][1]/text()" )".//span[@class='rating_num'][1]/text()" )print ("电影:" , title[0 ], "评分:" , score[0 ])else :print ("请求失败" )def run (self ):for index, url in enumerate (self .url_list, 1 print ("第" + str (index) + "页" ) self .get_page_data(url)if __name__ == "__main__" :
运行的部分结果便是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 第1页
注意,请将爬虫运用于正确的领域 >_<